论文开源
相信很多学生党都被论文复现折磨过。
好不容易找到几篇和自己研究方向相关的论文,结果 10 篇里可能有 9 篇没开源代码。
有的虽然建了开源仓库,但里面只有一个 README,正文就一句 coming soon,然后几年过去还是没更新。
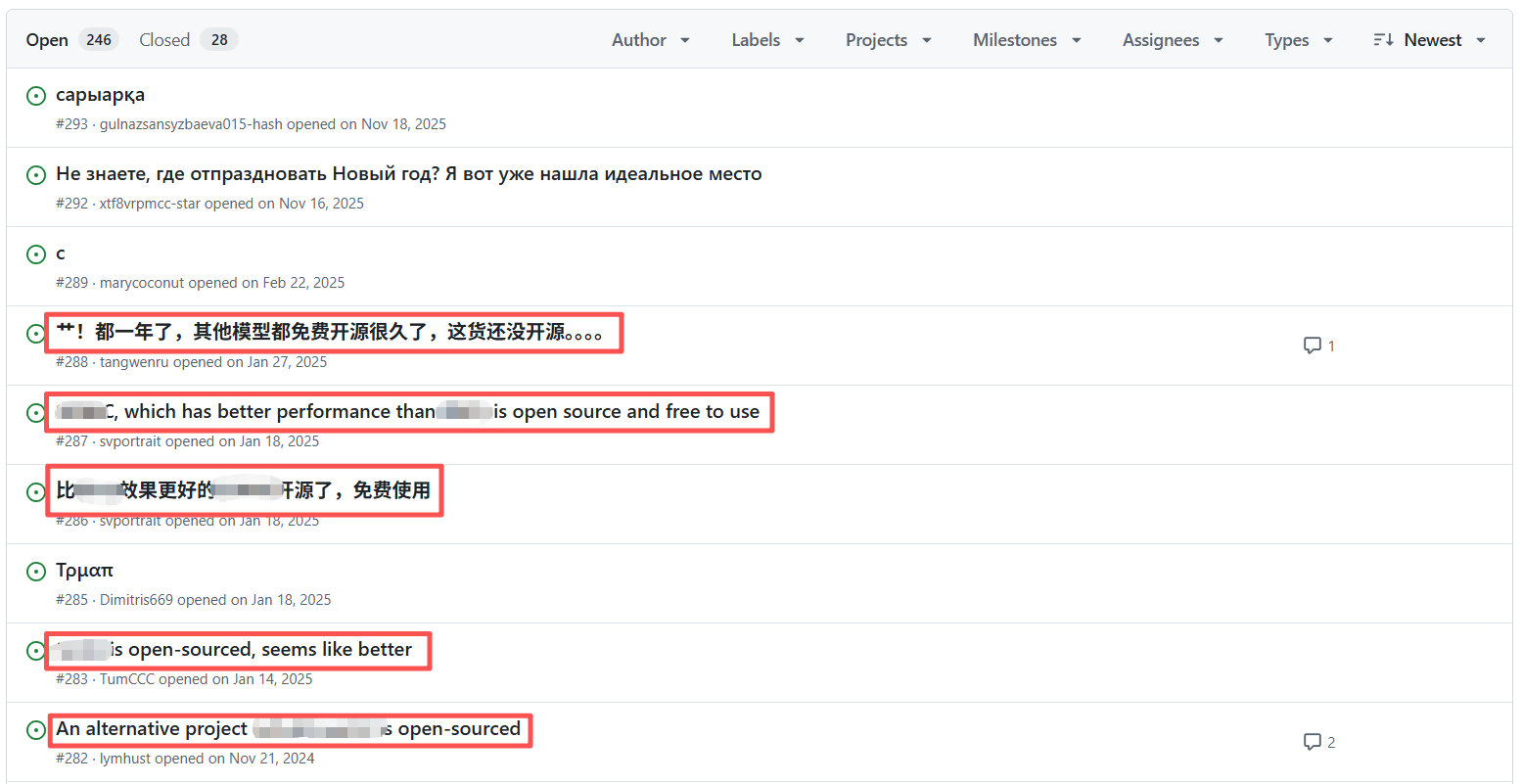
让人等得花儿都谢了。有人直接开 issue 吐槽,也有人在 issue 区打广告,顺便推荐自己更好且已开源的仓库。
还有些虽然开源了代码,但没有说明文档,或者文档写得非常混乱,根本不知道怎么跑。
也有的是代码看起来开源了,但里面一堆 Bug,根本跑不起来,好像生怕你真复现成功。
还有的只开源推理代码,训练代码完全不放。
有的是训练代码给了,但训练数据没给。这个倒也能理解,毕竟有些数据集涉及版权,确实不能随便开源。
这里又想起一个冷笑话:在大模型 AI 时代,别问模型训练数据是什么,就像别问别人年龄和薪资,不礼貌。
还有些是全开源了,但你跑出来的结果和论文差得很远,依旧复现不了。
如果你碰到一篇论文:训练代码、推理代码、消融代码、预训练权重、数据集、可视化结果、训练日志、脚本工具全都齐,那真的是神级开源。
当然,开源并不是强制义务,也不能要求每篇论文都开源。毕竟这是研究者的劳动成果,有些还涉及公司项目、商业版权或专利,确实没法随便放出来。
还有些情况是时间太赶:论文先发了,代码和文档来不及整理,后面又被各种事情拖住,就一直没补上。
说实话,虽然开源现状不算理想,但也不能把锅全甩给研究者,大家都有自己的工作节奏和生活压力。
所以别太苛责别人。开源是美德,但不是硬性义务。与其只盯着“有没有开源”,不如更多关注论文本身的内容和创新价值。
代码复现
如今,AI Agent,特别是 Code Agent 的能力越来越强。
现在借助 Claude Code(以下简称 CC)这类顶级编程工具,论文复现的门槛确实已经大幅降低。
最近几天,我一直在用号称地表最强编程 Agent 的 Claude Code(Opus 4.6)做论文复现。
但实际用下来发现,CC 解析论文很慢,还会把部分公式搞错,害得我人工纠正了好几次,浪费了不少时间和 Token。
后来我突然意识到一个很好用、但经常被忽略的复现技巧,必须分享给大家。
妙招分享
不知道大家平常是怎么复现论文的。
是不是跟我一样,直接把论文的 ArXiv 链接或者 PDF 甩给 CC。
然后你会发现,CC 会自动 fetch 论文 PDF,再转成文本去理解内容。
问题是,PDF 解析往往要等好几分钟。尤其是复杂论文里公式、图表很多,CC 会消耗大量时间和 Token。
更麻烦的是,PDF 排版和公式一复杂,CC 还可能解析错,最后对论文理解出现偏差。
后来我才想起来:ArXiv 投稿时,作者本来就要上传论文的 LaTeX 源文件。
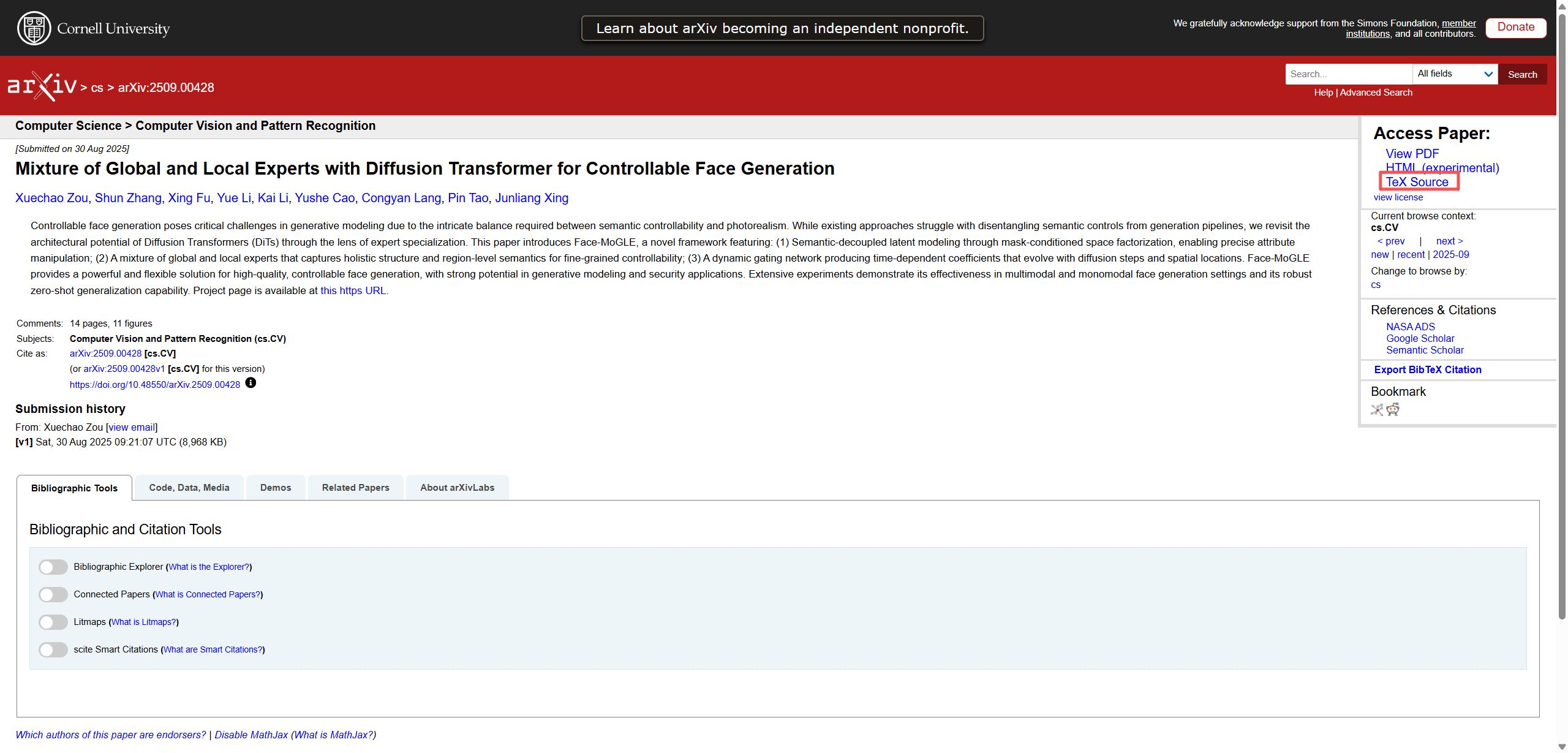
ArXiv 上每篇论文的 PDF 页面里,基本都有一个 TeX source 链接,点进去就能下载 LaTeX 源文件。
你把这个 LaTeX 源文件直接喂给 Claude Code,它就能按源码结构去解析,理解会更准。
这样一来,不仅能省下大量解析 PDF 的时间和 Token,还能明显提高复现准确度。
这次算是后知后觉,但真的很实用。
