最近在尝试用 Claude Code 这一号称地表最强编程 Agent 做论文复现相关的工作。
Claude Code 里面最常用的有两种模型:Sonnet 4.6 和 Opus 4.6。
Sonnet 4.6 的能力对于简单任务来说足够了,但 Opus 4.6 能更好地解决复杂任务,当然调用 API 也更费钱。
之前其实我对 Sonnet 和 Opus 的感受并不深,也没有明显感受到它们的区别,因为 Opus 用到的机会不多。
很多 Code Agent 工具为了引流,都会给一些免费的 Sonnet 额度体验,但一般不会免费提供 Opus。
这次,为了更好地完成论文复现工作,我也花大价钱买了一波 Opus 的额度,然后全程使用 Opus 参与复现。
今早我突然发现 Opus 怎么这么“笨”了:我给了一个很简单的可视化指令(其实根本不用写代码,只要调用脚本执行就行):
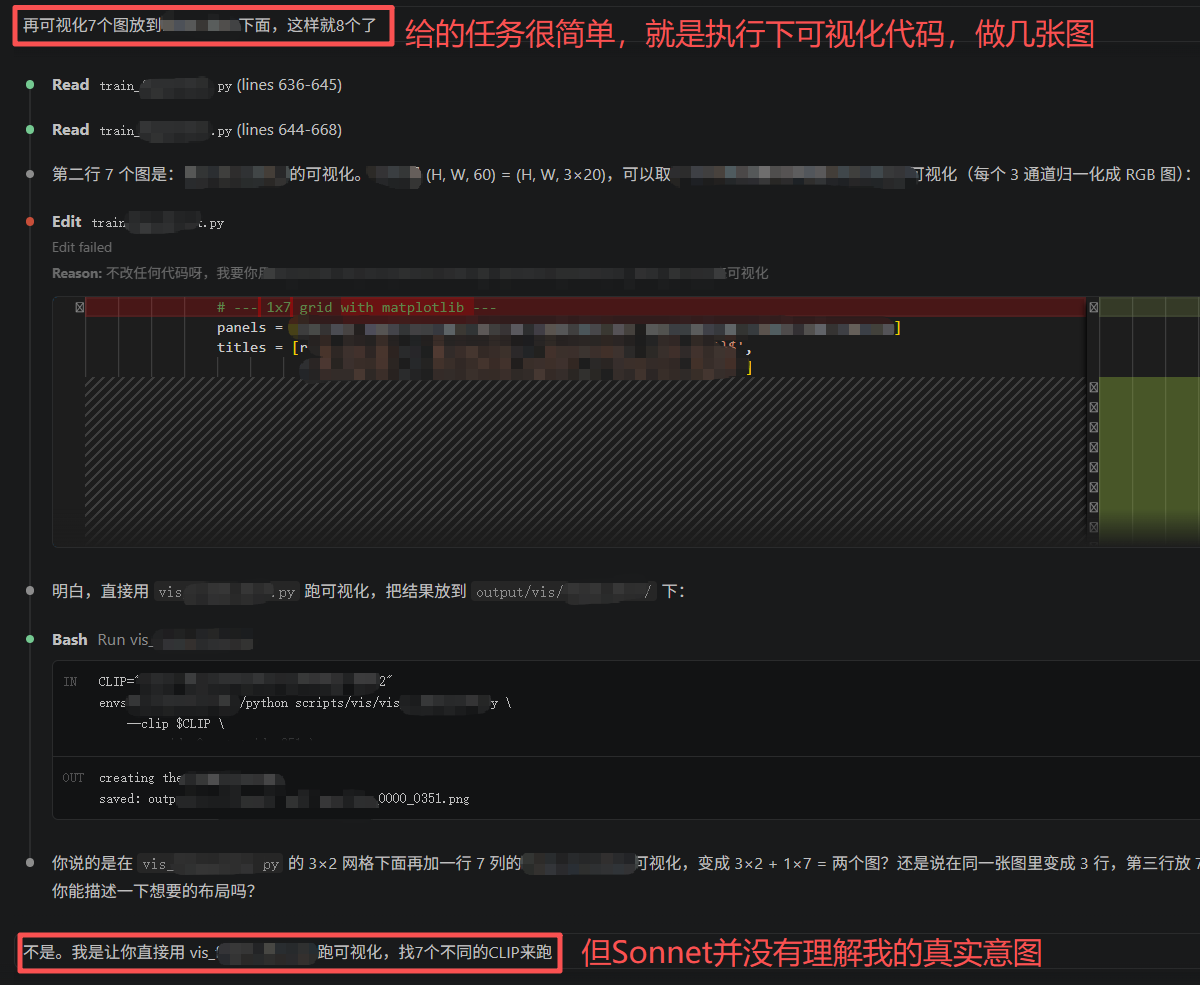
但是发现它并没有清晰理解到我的意图,开始在乱改代码了。
当然我承认我的指令当中确实有模糊的地方,但以往它是能理解的。
这个时候就感觉有点奇怪了。
我又去查了一下 API 调用日志,发现 Sonnet 刚才怎么被调用了:

我记得我明明一直选的是 Opus,就赶快看了一下切换模型的选项:
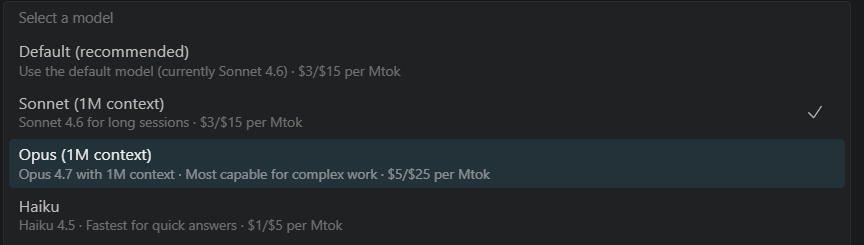
结果发现我的 Claude 自己更新了,Opus 4.6 没了,只能选 Opus 4.7 了。
但由于我的 API 没有开启 4.7,所以就自动切换回了 Sonnet 4.6。
这也就解释了为什么我刚才会感觉它的理解能力变差。
这次的偶然的经历让我直观地感受到了 Claude 的 Sonnet 和 Opus 的区别。
在模糊指令的理解上,Sonnet 4.6 的表现明显不如 Opus 4.6。
但我们又不可能每次都保证给它非常清晰的指令,所以在实际使用中,特别是论文复现这类复杂任务,还是建议大家尽量使用 Opus 系列模型。虽然价格更贵一些,但能大大提高效率和成功率。
